Projects Showcase
Turkish Morphological Tokenizer
A context-aware analyzer using Finite State Transducers and Viterbi-based POS disambiguation. It algorithmically models Turkish phonetic rules and resolves polysemy in 65k+ roots.
View Repository Also look data pipelineProject Overview
This research project addresses the complexity of agglutinative morphology in Turkish. By combining Finite State Transducers (FST) with probabilistic disambiguation, we achieve high-accuracy segmentation without the massive compute requirements of LLMs.
- Core Tech: FST for phonology, Hidden Markov Models for disambiguation.
- Dataset: Custom 65k+ root lexicon derived from Kaikki, Zemberek, and TDK.
- Impact: Provides a lightweight, interpretable alternative to neural tokenizers.
Why is this hard?
Turkish is an agglutinative language where a single word can correspond to an entire English sentence (e.g., "çekoslovakyalılaştıramadıklarımızdanmışsınızcasına").
- Ambiguity: A single surface form can have dozens of valid parses.
- Phonetic Harmony: Vowel harmony and consonant changes create a massive search space.
- OOV Issue: Dictionary-based lookups fail on productive derivations.
Approach
We built a two-stage pipeline:
- 1. FST Generation: Using Pynini, we model phonological rules (vowel harmony, drops) as state transitions. This generates all possible parses for a word.
- 2. Disambiguation: A Viterbi decoder scores path probabilities based on bigram POS statistics trained on the BOUN corpus.
- 3. Rule Engine: A final rule-based layer handles edge cases like proper nouns and date formats.
Key Metrics
- Status: Research in progress.
- Focus: Phonological rule coverage and disambiguation logic.
Ablation Studies
To validate components, we disabled parts of the pipeline:
- Without Viterbi: Accuracy drops to ~70% (random selection of valid parses).
- Without Phonological Rules: Coverage drops significantly on complex derivations.
Lessons Learned
- Data Quality > Model Complexity: Cleaning the lexicon gave higher gains than tweaking the HMM.
- Hybrid is Robust: Combining FST (exact) with Probabilistic (guess) handles both seen and unseen words best.
- Interpretability matters: Unlike BERT tokenizers, we can debug exactly why a word was split a certain way.
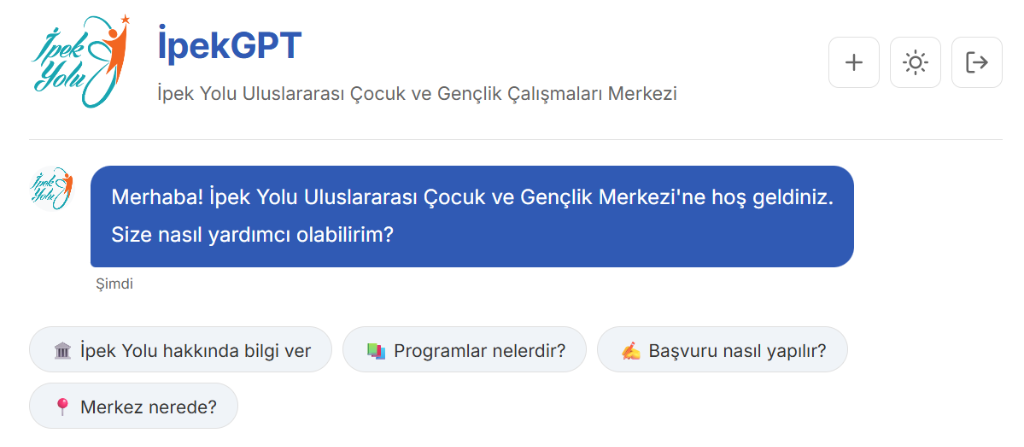
İpekGPT
LLM-based chatbot for İpek Yolu Entrepreneur Incubation Center. Features RAG architecture for accurate, context-aware responses.
Projects
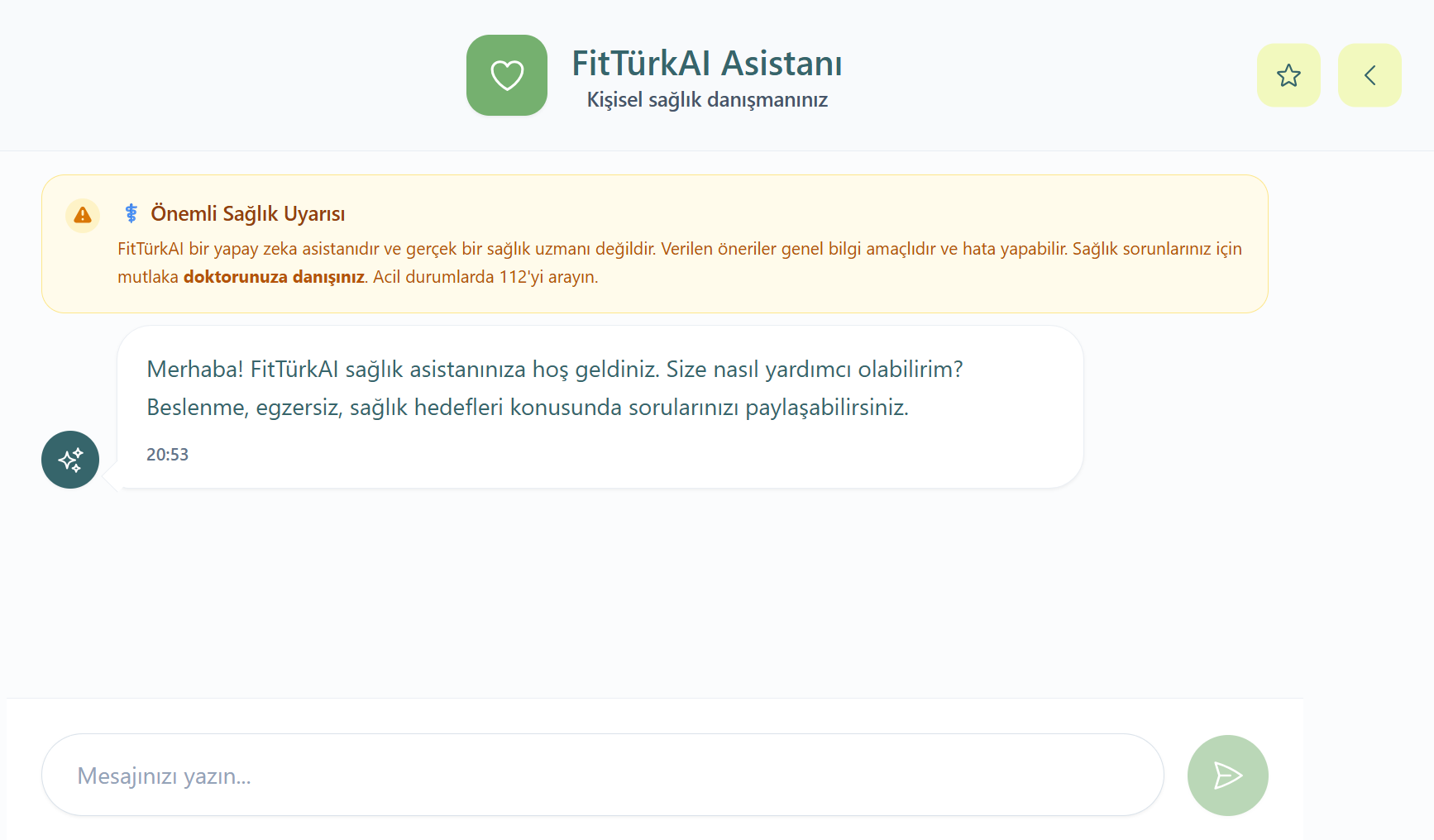
FitTurkAI
Personalized nutrition assistant combining RAG and fine-tuned CosmosGemma for task-focused dietetic advice.
TECH STACK- Fine-tuned CosmosGemma 2B model for dietetic expertise.
- RAG pipeline processing 40+ nutrition PDFs.
- Personalized meal planning based on biometrics.
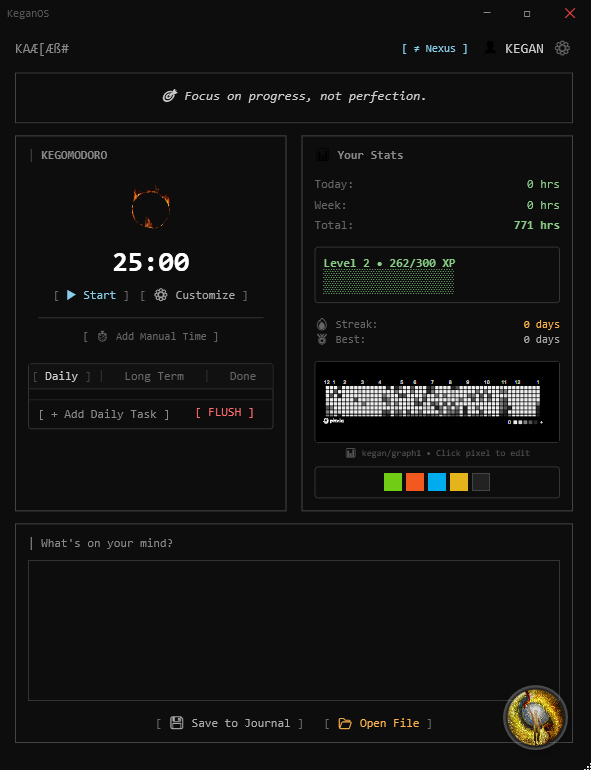
Personal OS
RAG-powered AI productivity dashboard with built-in notes, journaling, and integrations with KEGOMODORO and Pixe.la.
TECH STACK- Hybrid retrieval (Vector + Keyword) for high accuracy.
- Sub-200ms latency on production deployment.
- Context-aware conversation history management.
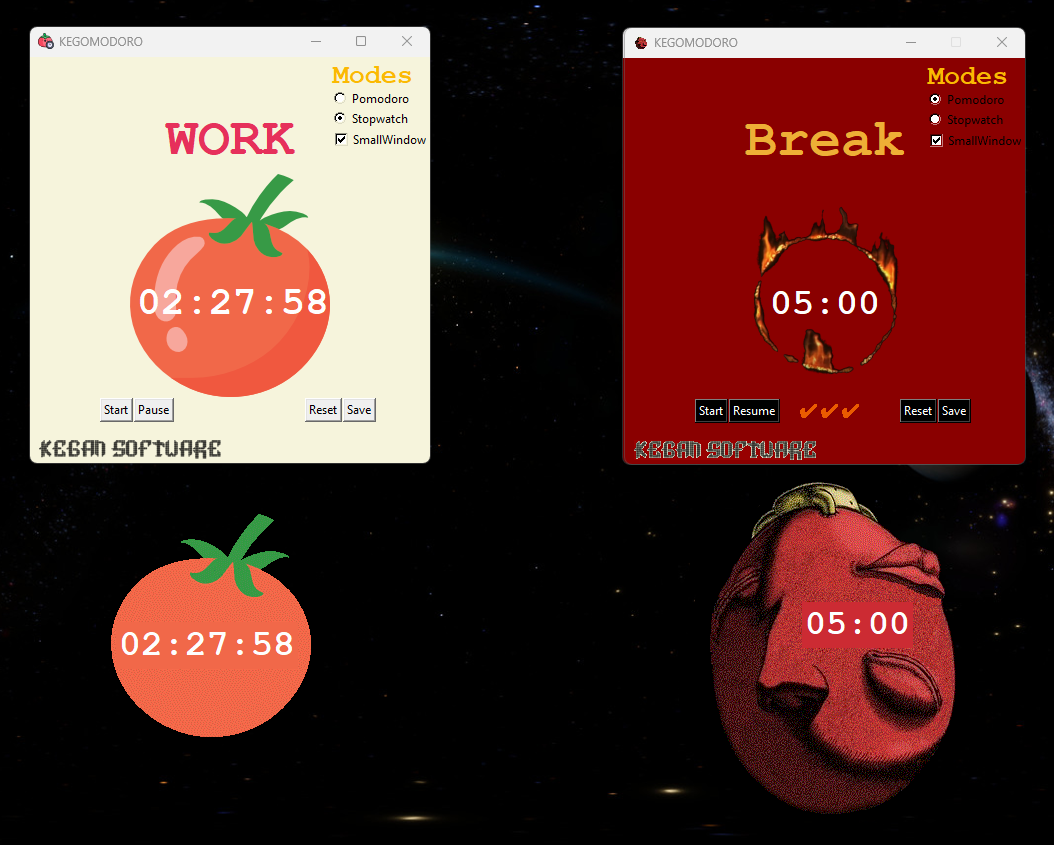
KEGOMODORO
Customizable Pomodoro timer with Pixela integration for productivity tracking. Features custom themes, stopwatch mode, and full personalization.
TECH STACK- Real-time Pixela graph integration for habit tracking.
- Customizable themes and focus/break intervals.
- Electron-based cross-platform architecture.
Click to see how it works